Hintergrund
Die Idee zu diesem R-Paket kam mir bei meiner Beschäftigung als Lesepate an einer Berliner Grundschule. Die Kinder, die ich betreue, können in der dritten Klasse zum Teil noch sehr schlecht lesen. Ich habe angefangen, mit Karteikarten zu arbeiten, auf die ich Wörter oder Silben schrieb. Ich hatte den Eindruck, dass es ein bisschen funktioniert hat und dass es den Kindern etwas Spaß gemacht hat, mit den Karten zu arbeiten. Ich habe festgestellt, dass es sehr viele verschiedene Wörter und Silben gibt und ich habe mich gefragt, welche ich aufschreiben sollte, welche wohl am “wichtigsten” sein könnten, weil sie am häufigsten vorkommen.
Die Häufigkeit der Wörter und Silben hängt natürlich von dem Text oder der Menge von Texten ab, die ich betrachte. Ich dachte mir, dass es zielführend sein könnte, wenn ich mir genau den Text angucke, den die Kinder in der Schule als nächstes lesen würden.
Dieses Paket enthält Funktionen, die die Wörter in einem vorgegebenen Text zählen oder sie in Silben zerlegen und dann die Silben und deren Arten (Vorsilbe, Nachsilbe, “innere” Silbe, eigenständiges Wort) zählen.
Im Folgenden möchte ich zeigen, wie das geht.
Bereitstellen eines Textes
Als erstes benötigen wir einen Text. Ich habe im Internet einen frei zugänglichen Text gefunden unter dieser Adresse: https://www.zitronenbande.de/kater-leo-arzt/
Ich habe eine Funktion geschrieben, die den Text aus dem Internet
lädt. Im ersten Schritt lesen wir den gesamten Text in die Variable
raw_text ein:
raw_text <- wordcards:::read_story_kater_leo_arzt()Der Text entspricht einer langen Zeile, von der wir hier mal nur die ersten 80 Zeichen ausgeben:
writeLines(substr(raw_text, 1L, 80L))
#> Eigentlich begann der Tag für Kater Leo richtig gut. Er rekelte sich nochmal ordZerlegen des Textes in seine Wörter
Als nächstes zerlegen wir den Text in seine Wörter, wobei alle Interpunktionszeichen (Punkt, Komma, Fragezeichen, usw.) sowie Ziffern ignoriert werden.
words <- wordcards:::text_to_words(raw_text)Der Text hat insgesamt 1367 Wörter. Die ersten sind:
head(words)
#> [1] "Eigentlich" "begann" "der" "Tag" "für"
#> [6] "Kater"Die letzten Wörter des Textes sind:
tail(words)
#> [1] "und" "freute" "sich" "auf" "sein" "Zuhause"Häufigste Wörter
Wir können bereits sehr einfach die häufigsten Wörter ermitteln:
Zuerst werden die verschiedenen Wörter mit table()
gezählt, dann werden die entsprechenden Haufigkeiten mit
sort() aufsteigend sortiert. Schließlich werden die letzten
(also häufigsten) Wörter mit tail() geholt und
ausgegeben.
Als Vorbereitung für die Erstellung der Karteikarten wird eine
Tabelle erzeugt, die die Wörter (word), absteigend nach
ihrer Häufigkeit (frequency) sortiert, zusammen mit ihrer
Häufigkeit und mit der Anzahl ihrer Buchstaben (nchar)
enthält.
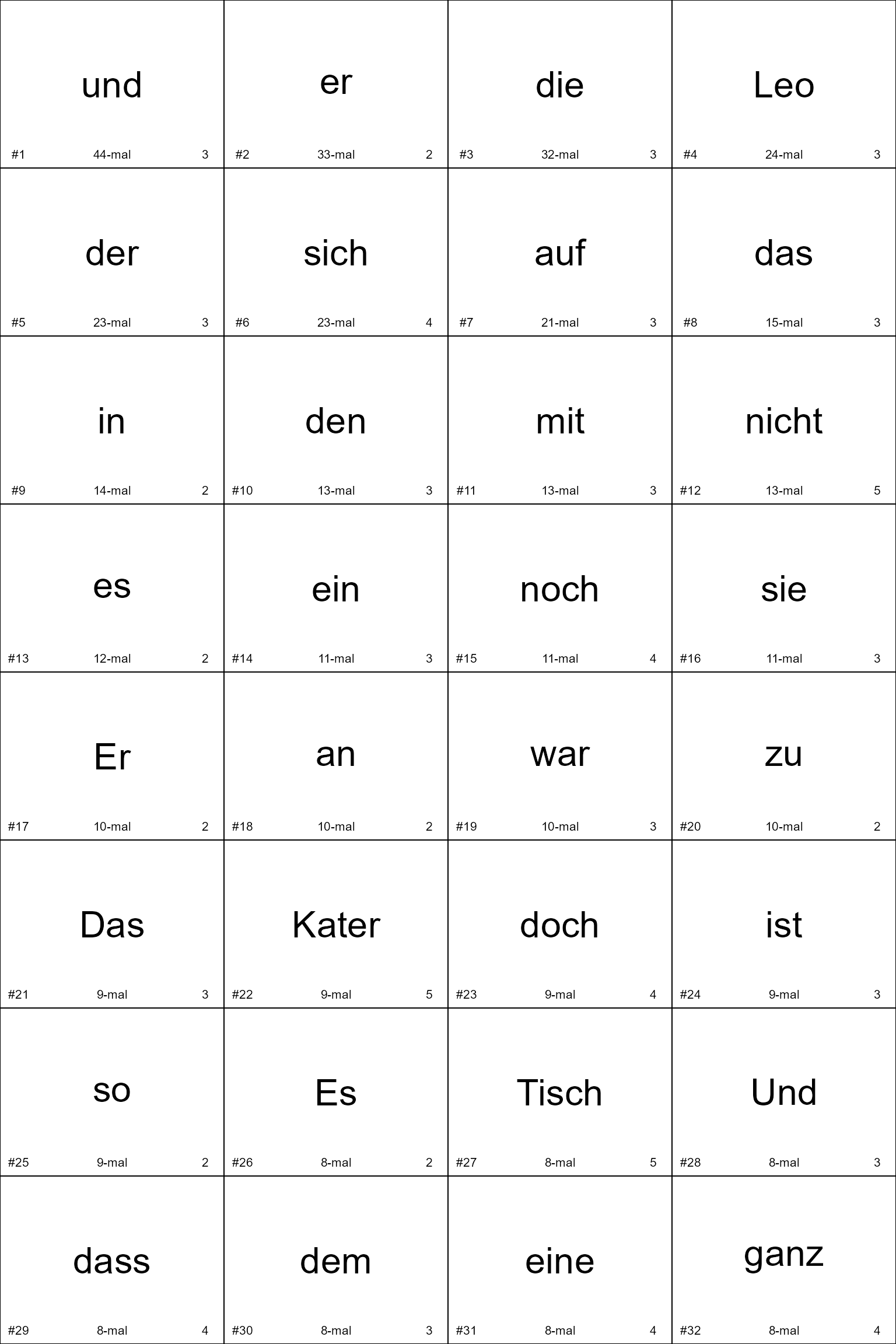
word_table <- wordcards:::words_to_word_table(words)Hier seht ihr die vollständige Tabelle:
DT::datatable(word_table)
n <- 32
wordcards:::plot_word_cards(
words = word_table$word[1:n],
frequencies = word_table$frequency[1:n],
both_cases = FALSE,
to_pdf = FALSE,
cex = 3
)